きました pic.twitter.com/mN83GXKkkn
— umemak (@umemak8) December 13, 2019
3年連続3回目の参加。 毎年会場が変わって、今年は渋谷です。表参道駅から歩きましたが。。
基調講演 13:00 - 13:45
藤門 千明 取締役 常務執行役員、CTO(チーフテクノロジーオフィサー)
- https://www.slideshare.net/techblogyahoo/yjtc19-in-shibuya-yjtc
- 「未来を、共に創ろう」
- ユーザーアクションの最大化
- オフラインにも進出(PayPay)
- MUU5049万、MUB9302万, DR1132億
- 未来をす作るためになければならないもの
- AI,データ
- 価値を届けるスピードを大事にしている
- 5年前は鈍化していた
- モダナイゼーション
- 過去のモダナイゼーション
- 失敗例
- 2013年、アプリケーションライフサイクルマネジメントの実現
- 常に最新のOS.HW・SWへ追従するための土台づくりが未完了
- うまく行かない3つのレガシー
- マインド、テクノロジー、習慣のモダナイゼーションを同時並行してすすめる
- 2013年、アプリケーションライフサイクルマネジメントの実現
- 失敗例
- マインドのモダナイゼーション
- 2015年12月、決起集会を開催を2000人集めて実施
- 会場はここ(ベルサール渋谷ファースト)だった
- トップからメッセージング
- 自分ごと、オープン化、チャレンジ
- 仮想化、CIのチャレンジが成功したのは、潜在的にエンジニアがいたから
- テクノロジーのモダナイゼーション
— umemak (@umemak8) December 13, 2019
- 方針は作るが、やり方はみんなで考える
- 一人で全部やると、スピードが出せない
- ZLAB設立
- 全て1から作らずMake or Useを使い分ける
- 全体スケジュールと優先度のみ決め、詳細は現場で考える
- 習慣のモダナイゼーション
- 負債が増える習慣を変える
- なぜ取り組んでいるのか繰り返し伝え続ける
- エンジニア・デザイナー以外のメンバーにも伝える
— umemak (@umemak8) December 13, 2019
- ルールをシンプルにし、ドキュメントを残す文化にする
- 117あったガイドラインを精査・作成して30までに集約
- 負債が増えにくい開発手法を選択する
- ペアプロセットを100用意
- サービスとプラットフォームの衝突
- 「サービスを止めない」という同じ方向を向かせる
- マニフェストの作成
- 開始してどうなったか
- CI/CDの増加
- PaaS移行推進
- 高負荷時のスケーリング
- トラベルはマイクロサービス化を推進
- PayPayフリマ・モールはペアプロで手戻りを回避、リリースまでの時間を大幅短縮
- 失敗した施策もある
Kubernetes as a ServiceをProduction環境で2年活用し、直面してきた課題と解決策 14:00-14:30
勝田 広樹 テクノロジーグループ システム統括本部 クラウドプラットフォーム本部
- https://www.slideshare.net/techblogyahoo/kubernetes-as-a-serviceproduction2-yjtc19-in-shibuya-a1-yjtc-204740315
- ヤフーのKaaS
- 2年で500クラスタまで増加
- 今年の1月には200だった
- ノード数は8000VM以上
- KaaSはL Lab製
- 2年間の変化
- 利用者の増加
- システムの大型化
- 稼働サービスの多様化
- サポート領域の拡大
- 利用者の増加
- 直面した課題
— umemak (@umemak8) December 13, 2019
- K8sの知見
- 有効的な使い方がわからない
- 社内セミナーを定期的に開催
- 相談会の実施
- 最新のK8sを負い続ける
- Paas/FaaS on K8sの検討
- サポート範囲の不毛な拡大
- 利用者が自由なタイミングでバージョンを更新可能
- K8sは3ヶ月ごとにマイナーバージョンが上がる
- サービスが利用している最古のバージョンに引きづられる
- 定期的に一斉アップデートを実施
- 過剰なリソース要求
- 実利用しているリソース料を可視化して解決
- マイクロサービス化の弊害
- 調査の難しさ。どこで何が起きているのか把握しにくい。
- Dynatraceの導入
- パフォーマンス改善に強い
- 大量ログの集約
- 総合ログ管理PFへの流量が爆発
- 流量制御
- セキュリティ
- VM環境では脆弱性の自動検知を実施していた
- K8s環境ではヒトの手がかかる
- sysdigの導入
- まとめと今後
— umemak (@umemak8) December 13, 2019
ヤフオク!における出品時タイトル推薦機能の裏側 14:45-15:15
土井 賢治 テクノロジーグループ サイエンス統括本部 サイエンス2本部
- https://www.slideshare.net/techblogyahoo/yjtc19-in-shibuya-a2-yjtc-204721536
- 二郎の画像から店舗を当てるbot作ったひと
- 出品画像と類似した過去の出品画像の情報に基づいて推薦
- 特徴ベクトルを利用
- 良い特徴ベクトルを抽出するための工夫
- 高速に検索する工夫
- 画像から特徴ベクトルへの変換
- Metric Learning(距離学習)
- Triplet loss
- 商品のタイトル単語の重複具合を指標としてtripletを作成
- 分類学習
- 出品カテゴリを画像の見た目に基づいてマッピングしたラベルを使用
- それぞれの手法を検証
— umemak (@umemak8) December 13, 2019
- 分類学習のほうが良い結果が得られた
- CNN学習時の工夫
- 33000カテゴリを1300までマッピングして減らしている
- kukaiを利用して学習
- 最大80GPUで分散
- 重複した画像の除去
- 知覚ハッシュ関数
- 特徴ベクトルの近傍探索
- 線形探索ではコストがかかりすぎる
- NGT(Neighborhood Graph and Tree)
- ヤフーが開発しているOSS
- https://github.com/yahoojapan/NGT
- 類似画像検索基盤
- 商品のメタデータ保存には全社Cassandraクラスタを使っている
— umemak (@umemak8) December 13, 2019
- カテゴリも使って絞り込み
- 定型文(美品、送料無料など)をメタデータからは除去
- 今後の展開
- タイトル以外の推薦にも活用したい
メディアサービスの基盤としてのナレッジベースの活用と生成方法について 15:30-16:00
山崎 朋哉 メディアカンパニー 検索統括本部 検索プラットフォーム開発本部
- https://www.slideshare.net/techblogyahoo/yjtc19-in-shibuya-a3-yjtc-204745833
- 100以上のサービスとユーザーとのマッチングが大事
- 各サービスの行動ログから、各サービスのコンテンツを推薦したいた
- サービスをまたいでコンテンツを提供するための、ナレッジベース
- KBを使う理由
- 現実世界を構造化できる
- 構造の拡張ができる
- 推論ができる
- KB生成の流れ
- 課題
- 誤った情報の検出
- エンティティバリデーション、マッチング
- ルールベース、グラフベースのマッチング手法
- ユーザーの多様なニーズに答える
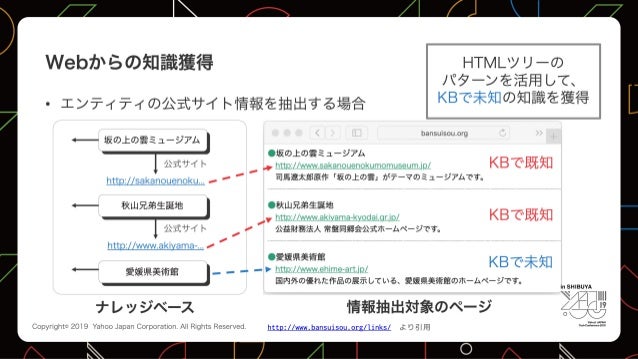
- すでにKBにあるデータをWeb上のデータで補完する
- 誤った情報の検出
- まとめ
— umemak (@umemak8) December 13, 2019
クロスユースプラットフォーム ~ 秒間10万リクエスト・レスポンスタイム100ms以下を実現するシステムについて ~ 16:15-16:45
大島 圭貴 コマースカンパニー 事業推進室 コマースマーケティング本部
- https://www.slideshare.net/techblogyahoo/10100ms-yjtc19-in-shibuya-a4-yjtc-204740653
- クロスユースプラットフォームとは
— umemak (@umemak8) December 13, 2019
- サービスをまたいで表示されるコンテンツ
- 10万rps
- PCFでGoでリクエストを受けている
- 2年前は3000rpsの要件だった
- PCFはクラスタ及びインスタンス数をスケーリング
- Cassandraはノード数を増やして対応
— umemak (@umemak8) December 13, 2019
- 2年前はレイテンシー要件は200msだった
- 複数のデータを個別に取得していて、ボトルネックになっていた
- ルールとコンテンツデータを結合して1回で取得するようにした
- 100ms要件への対応
- データをキャッシュして対応
- キャッシュ方法にも工夫が必要
- 期限切れへの対応
- L1,L2の2段キャッシュで対応
- L1: 現在有効なデータのみ保存
- L2: 未来のデータも保存
- ルールの複雑化・肥大化による取得時間の悪化
- ユーザーのクラスタリングで対処
- Cassandraデータ偏り
- ページごとに設定していたPartition Keyを変更
- ランダムIDを付加して複合キーにする
- 学び
- データストアへのアクセス回数を減らす
- キャッシュを効果的に使う
- データサイズを小さくできないか検討する
- データ構造の設計はデータストアの特性を理解して行う
広告サイエンスにおける統計的機械学習技術のご紹介 17:00-17:30
鈴村 真矢 テクノロジーグループ サイエンス統括本部 サイエンス2本部
- https://www.slideshare.net/techblogyahoo/yjtc19-in-shibuya-a5-yjtc-204740699
- AIと機械学習の違い
- AIのいち分野が機械学習
- YDN(Y!広告 ディスプレイ広告)
- Nは旧名称(ネットワーク)の名残
- CTR予測のための機械学習
- 広告がクリックされる確率
- 過去データから傾向を学習し、予測する
- うまく行かないパターン
- オフライン評価が良くてもライブテストでうまく行かない
- Ranking Bias と Negative Bias
- オフライン評価が良くてもライブテストでうまく行かない
- Ranking Bias
- 選んだ広告は、期待したよりクリックされない
- 真のCTRと予測CTRがずれる
- Negarive Bias
- ランキングが高い広告の予測を下げて学習しようとすると、全体の予測が下がる
- 下がるとそもそもランキング会のものは配信されずデ ータも取れなくなっていく
- 提案法
- 一度ランキングした結果に対して、バイアスをかけて再度抽出する
— umemak (@umemak8) December 13, 2019
- 効果あり
- データの偏りを補正するには、データの発生プロセスを理解することが大事
CtoCフリマアプリの作り方 〜6ヶ月間のPayPayフリマ開発を支えた設計〜 17:45-18:15
松田 悠吾 / 三宅 晃暉 コマースカンパニー ヤフオク!統括本部 フリマ推進本部
- https://www.slideshare.net/techblogyahoo/ctoc-6paypay-yjtc19-in-shibuya-a6-yjtc-204740829
- バックエンドの機能はヤフオクの流用ではなく、ほぼスクラッチで開発した
— umemak (@umemak8) December 13, 2019
- Kotlin+SpringFW
- コンポーネントを独立させることで、役割が明確になる
- ヤフオクとの連携
- クロスリテイリング
- 検索システムを共通にして実現
- BFFがヤフオクのAPIを叩いたりもする
- クロスリテイリング
- GraphQL
- 多種クライアントに対応するため
- 仕様変更・追加に強い
- Android Jetpack
- https://developer.android.com/jetpack?hl=ja
- 品質、コード量に効果あり
- マルチモジュール
- マージコスト削減、依存関係の明確化
- DIフレームワーク
- Daggerを使用
- https://dagger.dev/